
python学习使用正则表达式
正则表达式:
又称规则表达式,是处理字符串的有力工具,是对字符串操作的一种逻辑公式。
本质:使用事先定义好的一些特定字符组成的“规则字符串”的一种过滤逻辑
规则字符串:包括普通字符(如:a~z之间的英文字母,数字)和特殊字符(称为“元字符”)
例:
|
与python中提供的字符出处理函数相比,正则表达式提供了更强大的处理功能,可以快速、准确地完成复杂的查找、替换等处理任务,其逻辑性、灵活性、功能性强,而且能极简单的方式实现字符串的复杂控制
正则表达式处理字符过程:
编写正则表达式
使用正则表达式引擎对正则表达式进行编译,得到正则表达式对象
通过正则表达式对象对字符串进行匹配或过滤,得到匹配的结果
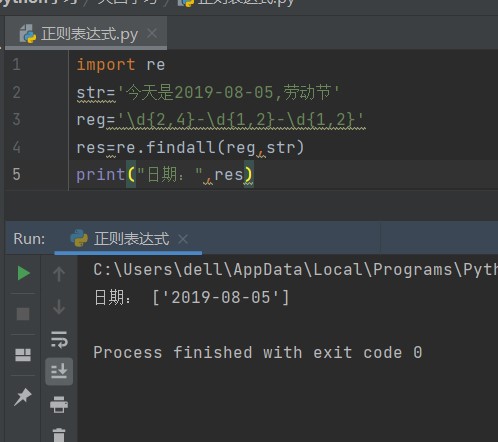
例:正则表达式提取字符串中的日期
正则表达式语法:
正则表达式组成:
正则表达式的构造方法和数学表达式的构造方法一样,使用多种元字符和运算符组合在一起创建一个表达式,组成表达式的可以是单字符,字符集合,字符范围、字符间的选择或者它们之间的任意组合
普通字符:
正则表达式中的普通字符:
- 英文字母:26个大小写英文字母共52个
- 汉字:Unicode字符集中包括的汉字
- 数字:0~9共十个数字
- 标点符号:如:”:” “,”等
- 其他符号:如:”\n(换行符)”\t(制表符)”等非打印字符
特殊字符:
有特殊含义的字符,特殊字符一般具有通用性:
字符匹配模式:
语法 解释 . 匹配除换行符(\n)外的任意单个字符 \ 表示位于\之后的为转义字符 | 匹配位于|之前或之后的字符 [] 匹配位于[]中的任意一个字符 [a-b]或[abc] 匹配指定范围的任何字符 [^a-c]或[^abc] 匹配指定范围外的任何字符 () 将()中的内容作为一个整体对待 \d 匹配一位数字 \D 与\d刚好相反 \w 匹配一位数字、字母、下划线 \s 匹配一位空白字符:<空格>,\t,\n,\r,\f,\v \S 与\s相反 \W 与\w相反 定位符:
语法 解释 ^ 匹配以^后面的字符或模式开头的字符串 $ 匹配以$前面的字符或模式结束的字符串 \b 匹配单词头或单词尾 \B 与\b相反 限定符:
语法 解释 * 匹配*前一个字符出现0次或多次 + 匹配+前一个字符出现一次或多次 ? 匹配?前一个字符只能出现一次或0次 {m} 匹配前一个字符只能出现m次 {m,} 匹配前一个字符出现至少m次 {m,n} 匹配前一个字符至少出现m~n次 扩展语法:
| 语法 | 解释 |
|---|---|
| (?#pattern) | 表示注释 |
| (?:pattern) | 匹配但不捕获该匹配的子模式 |
| (?=pattern) | 用于正则表达式之后,如果=后的内容在字符串中出现则匹配,但不返回=之后的内容 |
| (?!pattern) | 用于正则表达式之后,如果!之后的内容在字符串中不出现则匹配,但不返!之后的内容 |
| (?<=pattern) | 用于正则表达式之前,如果<=后的内容在字符串中出现则匹配,但不返回<=之后的内容 |
| (?<!pattern) | 用于正则表达式之前,如果<!后的内容在字符串中不出现则匹配,但不返回<!的内容 |
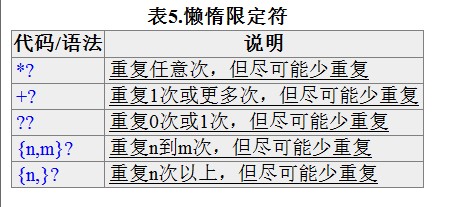
贪婪模式与非贪婪模式:
贪婪模式与非贪婪模式影响的是被量词修饰的子表达式的匹配行为
贪婪模式:在整个表达式匹配成功的前提下尽可能多的匹配
非贪婪模式:在整个表达式匹配成功的前提下,尽可能少的匹配
默认贪婪模式,在量词后面直接加上一个”?“就是非贪婪模式
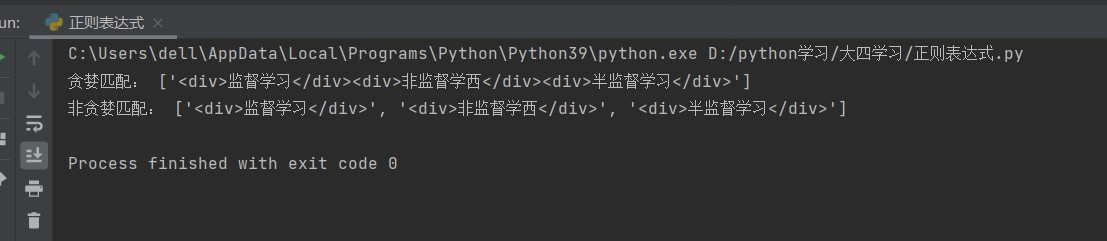
字符串的贪婪模式与非贪婪模式:
|
使用正则表达式模块处理字符串
使用标准库Re模块可以使用正则表达式全部功能:
- 直接调用re模块中的函数
- 将正则表达式编译程成正则表达对象后再调用表达式对象中的函数、
re模块中常用的函数:
匹配函数:
1、res=re.match(pattern, str,flags=0):功能是尝试从字符串的起使位置匹配一个模式,若匹配成功则返回一个匹配对象,否则返回None。pattern为正则表达式,str为匹配字符串,flags是可选标志位,用于控制正则表达式匹配方式,如区分大小写,多行匹配等。
正则表达式常用标志位:
| 修饰符 | 描述 |
|---|---|
| re.I | 使匹配对大小写不敏感 |
| re.L | 使本地化识别(locale-aware)匹配 |
| re.M | 多行匹配,影响^和$ |
| re.S | 匹配包括换行在内的所有字符 |
| re.U | 根据Unicode字符集解析字符影响\w,\W,\b,\B |
| re.X | ^匹配字符串和每行的行首,$匹配字符串和每行行尾 |
可以使用匹配对象的函数:
group(0):返回包含整个表达式的字符串
group(n1,n2,……):返回一个包含多个组号对应值的元组
groups():返回一个包含所有小组字符串的元组
groupdict():返回一个包含所有经命名匹配小组的字典
#使用re.match()匹配
import re
str = "0086-010-88668866"
mat = re.match(r"(?P<nation>\d{4,})-(?P<zone>\d{3,4})-(?P<numper>\d{7,8})",str,re.M|re.I)
if mat:
print("mat.group(0)",mat.group(0))
print("mat.group(1)", mat.group(1))
print("mat.group(2)", mat.group(2))
print("mat.group(3)", mat.group(3))
print("mat.group(1,2,3)", mat.group(1,2,3))
print("mat.groups()", mat.groups())
print("mat.groupdict()", mat.groupdict())
else:
print("match匹配不成功!")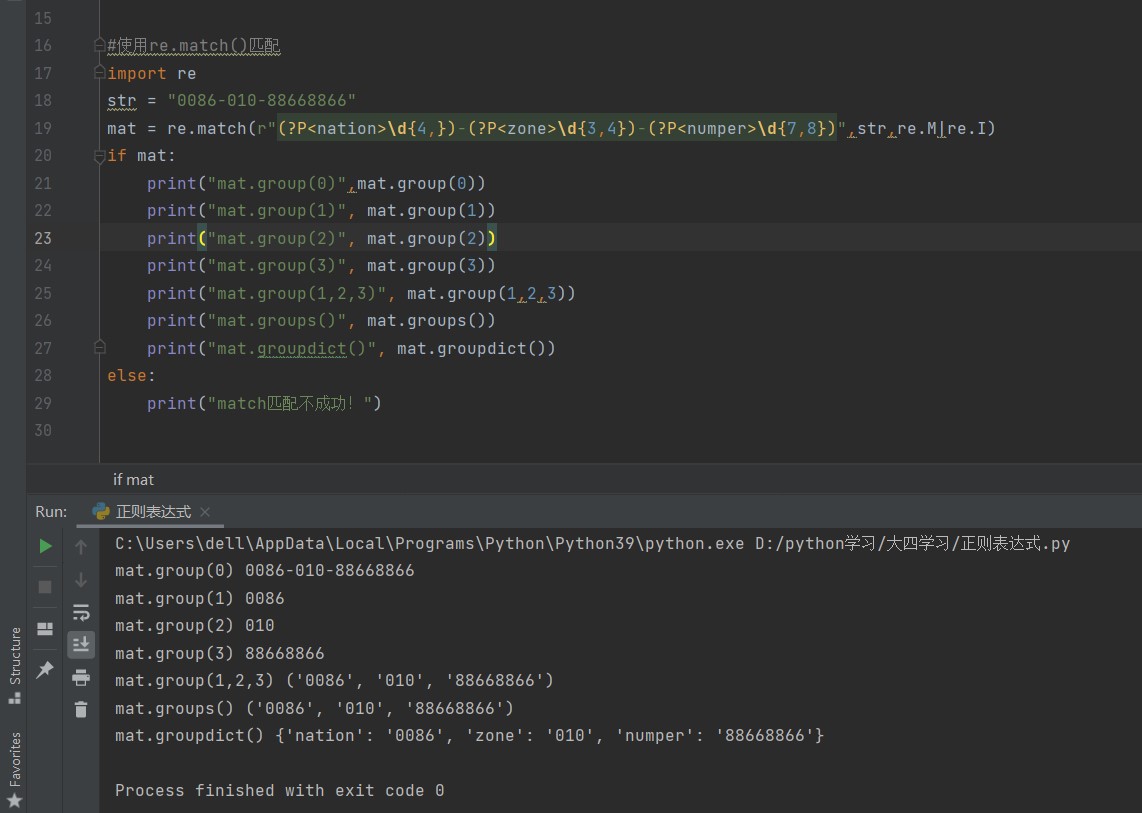
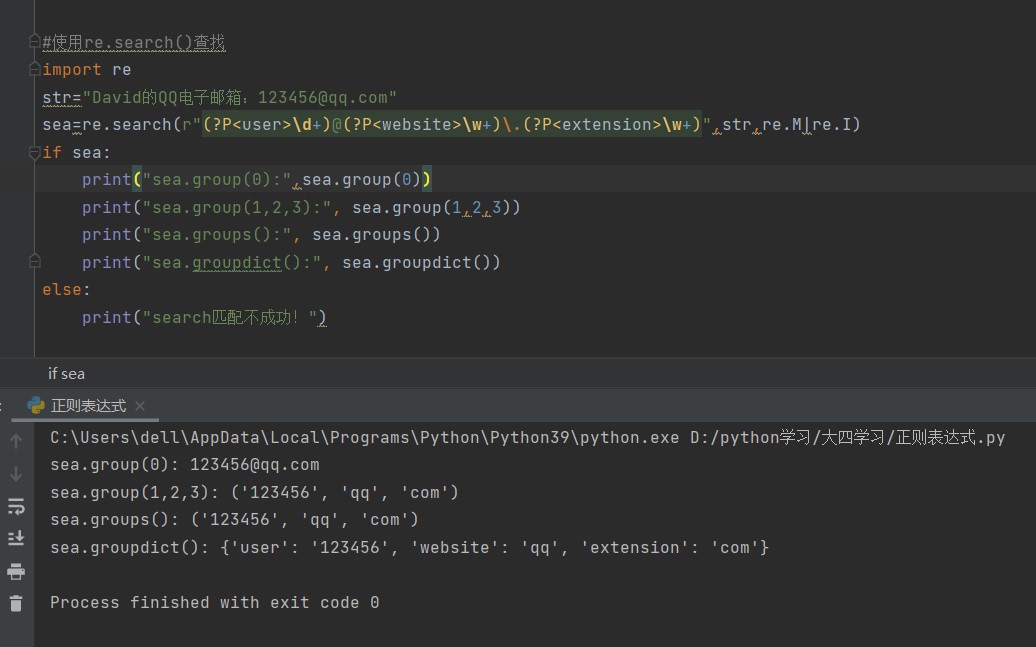
2、res=re.search(pattern,str,flags=0):功能扫描整个字符串并返回第一个成功的匹配对象。用法和re.match()函数相同
|
查找函数:
res=re.findall(pattern,str,flags=0):功能使在字符串中找到正则表达式匹配的所有子字符串,并返回一个列表:如果没有找到匹配,则返回空列表。参数和re.match()函数相同
注意:re.match()函数和re.search()函数就是返回一次匹配的结果,re.findall()返回所有匹配结果
#使用re.findall函数
import re
res=re.findall('\w+','liv well,love lots,and laugh often')#查找匹配字符串
print("匹配结果:",res)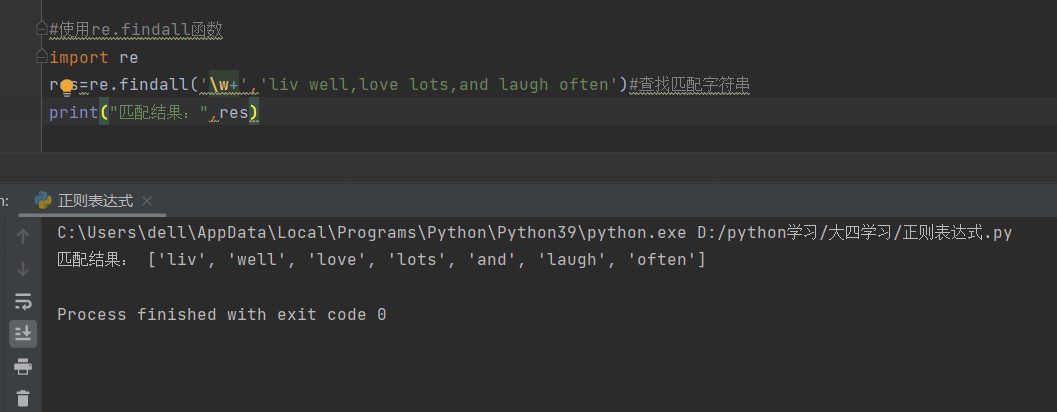
res=re.finditer(pattern,str,flags):功能是在字符串中找到正则表达式匹配的所有子字符串,并作为一个迭代器返回,参数和之前一样
#re.finditer函数:
import re
str="of the people,for the people,by the people"
res=re.finditer("\w+ \w+ (people)",str)
for match in res:
print(match.group())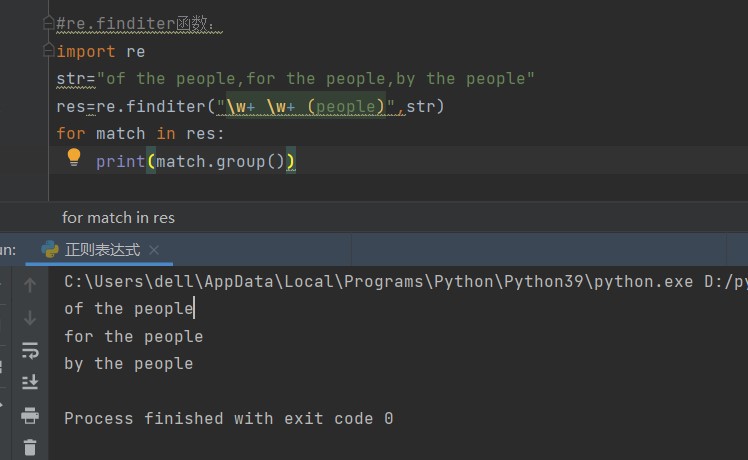
替换函数:
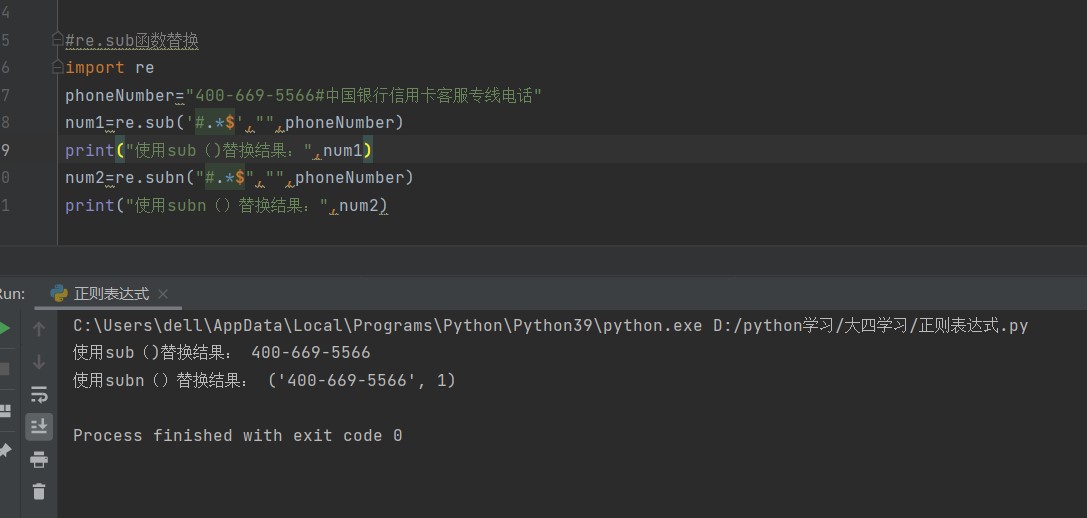
- res=re.sub(pattern,repl,str,[,count=0]):功能是将pattern的匹配项用repl替换,返回新字符串,pattern为正则表达式,repl为替换字符串,str为被查字符串,conunt为模式匹配最大次数,默认0为替换所有的匹配
- res=re.subn(pattern,repl,str,[,count=-0]):功能将pattern匹配项用repl替换返回包含新字符串和替换次数的二元组,参数和上方一样
|
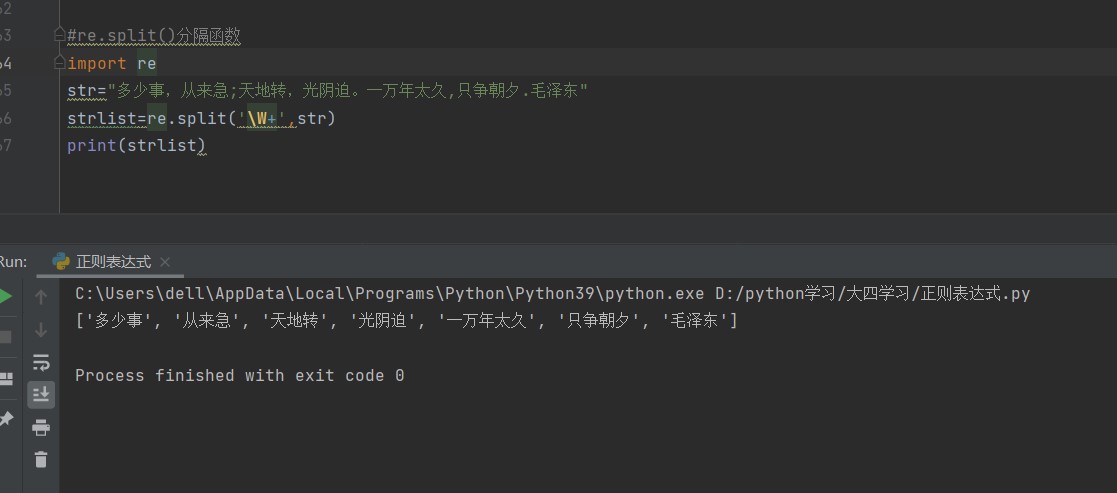
分割函数:
res=re.split(pattern,str,[,maxsplit=0,flags=0]):功能通过指定分隔符对字符串进行分隔并返回分隔结果列表,pattern为正则表达式,包含指定的分隔符,str为待分隔的字符串,maxsplit为分隔次数,默认为0,不限制次数,flags为可选标志位
|
编译函数:
re.compile(pattern,[,flags]):用于编译正则表达式,生成一个正则表达是对象,pattern为正则表达式,flags参考上面正则表达式常用标志位表格。
|
常用的正则表达式:
